Name: Quast, Johannes
Martrikelnummer: 6897847
Abgabedatum: 29.05.2022
- es darf nicht auf andere Kapitel als Leistungsnachweis verwiesen werden (z.B. in der Form "XY wurde schon in Kapitel 2 behandelt, daher hier keine Ausführung")
- alles muss in UTF-8 codiert sein (Text und Code)
- sollten mündliche Aussagen den schriftlichen Aufgaben widersprechen, gelten die schriftlichen Aufgaben (ggf. an Anpassung der schriftlichen Aufgaben erinnern!)
- alles muss ins Repository (Code, Ausarbeitung und alles was damit zusammenhängt)
- die Beispiele sollten wenn möglich vom aktuellen Stand genommen werden
- finden sich dort keine entsprechenden Beispiele, dürfenl auch ältere Commits unter Verweis auf den Commit verwendet werden
- Ausnahme: beim Kapitel "Refactoring" darf von vorne herein aus allen Ständen frei gewählt werden (mit Verweis auf den entsprechenden Commit)
- falls verlangte Negativ-Beispiele nicht vorhanden sind, müssen entsprechend mehr Positiv-Beispiele gebracht werden
- Achtung: werden im Code entsprechende Negativ-Beispiele gefunden, gibt es keine Punkte für die zusätzlichen Positiv-Beispiele
- Beispiele
- "Nennen Sie jeweils eine Klasse, die das SRP einhält bzw. verletzt."
- Antwort: Es gibt keine Klasse, die SRP verletzt, daher hier 2 Klassen, die SRP einhalten: [Klasse 1] , [Klasse 2]
- Bewertung: falls im Code tatsächlich keine Klasse das SRP verletzt: volle Punktzahl ODER falls im Code mind. eine Klasse SRP verletzt: halbe Punktzahl
- "Nennen Sie jeweils eine Klasse, die das SRP einhält bzw. verletzt."
- verlangte Positiv-Beispiele müssen gebracht werden
- Code-Beispiel = Code in das Dokument kopieren
Das Projekt "ASE Reinforcement Learning" soll ein einfaches CLI zur Verfügung stellen, mit dem Jeder typische Beispiele (aktuell nur zwei) des Reinforcement Learnings ausprobieren und über einige Parameter anpassen kann. Das Ergebnis des Trainings wird als CSV zur Verfügung gestellt und kann anschließend für andere Projekte genutzt werden. Auch können, basierend auf bestehenden Beispielen, eigene Beispiele erstellt werden.
Über verschiedene Kommandos, die im folgenden näher gezeigt werden, kann der Nutzer verschiedene Aktionen ausführen. Im Moment beschränkt sich dies auf folgende Kernpunkte:
- Anzeigen von Informationen über die Applikation
- Welche Agenten stehen zur Verfügung?
- Welche Environments stehen zur Verfügung?
- Welche Algorithmen stehen zur Verfügung?
- Welche Einstellungen in der Config gibt es?
- Starten eines Trainings
- Starten einer Evaluation
Requirements:
- Java 16+
- Maven
- Die JAR muss ausreichend Berechtigungen besitzen, um im aktuellen Verzeichnis einen weiteren Ordner zu erstellen
git clone https://github.com/jatsqi/ASE-Reinforcement-Learning.gitmvn package cd 4-ase-reinforcement-learning-plugin/targetDie JAR hat standardmäßig den Namen 4-ase-reinforcement-learning-plugin-1.0-SNAPSHOT-jar-with-dependencies.jar
mvn testBefehle anzeigen:
java -jar <jar>Agenten auflisten:
java -jar <jar> agentUmgebungen auflisten:
java -jar <jar> envAlgorithmen auflisten:
java -jar <jar> algorithmConfig bearbeiten (Key(s) auflisten):
java -jar <jar> config get [KEY]Config bearbeiten (Keys setzen):
java -jar <jar> config set <Key>Parameter für Training/Evaluation auflisten:
java -jar <jar> run Training in beliebiger Grid-World starten:
java -jar <jar> run --agent 2d-moving-agent --environment grid-world --steps 1000000 --envopts height=10,width=10Training in abgespeicherter Grid-World aus einer Datei starten:
java -jar <jar> run --agent 2d-moving-agent --environment grid-world --steps 1000000 --envopts from=examples/maze.gridTraining in K-Armed-Bandit Umgebung starten:
java -jar <jar> run --agent pull --environment k-armed-bandit --steps 100000 --envopts bandits=10Training aus gespeicherter Policy (Beispiel-ID: 5) fortsetzen (Beispiel: Grid-World):
java -jar <jar> run --agent 2d-moving-agent --environment grid-world --steps 1000000 --envopts from=examples/maze.grid --resume 5[allgemeine Beschreibung der Clean Architecture in eigenen Worten]
Als Clean-Architecture wird eine extrem vielseitige und anpassungsfähige Architektur bezeichnet, nach der sich viele Anwendungen sauber und vorallem wartbar, bzw. erweiterbar modellieren lassen. Größere Projekte bestehen häufig aus vielen unterschiedlichen Komponenten wie z.B. Datenbankanbindung, Models, Factories, UI bzw. einer Anzeigekomponente o.ä., die sich mitunter unabhängig voneinander entwickeln lassen. Besonders in modernen Applikation besteht das Problem, dass Entwickler mit Tools wie z.B. Maven dazu verleitet werden, sämtliche Komponenten miteinander zu "verweben" oder externe Frameworks zu benutzen, von dem die entwickelten Komponenten abhängig werden. Aus bequemlichkeit gelangt so häufig Applikationslogik z.B. in das UI, welches sich eigentlich nur um die Anzeige kümmern sollte. Soll spätere die gundlegende Technologie wie z.B. das Framework oder Bestandteile des UI geändert werden, so können selbst Komponenten, die dieses eigentlich nicht benötigen, davon betroffen sein.
Um diese Abhängigkeit zwischen verschiedenen Komponenten oder auf bestimmte Technologien zu brechen, kann eine Applikation "clean" in verschiedene Ebenen eingeteilt werden, die häufig die folgenden Aufgabenbereiche getrennt voneinander wahrnehmen:
- Eine Ebene, die die Domäne darstellt und technologisch unabhängige, langlebige Komponenten bereitstellt, die unabhängig von dem genutzten UI o.ä. funktionieren. Auch sollen hier die verschiedenen Invarianten sichergestellt werden, sodass bestimmte Objekte keinen inkonsistenen Zustand erreichen.
- Eine Ebene, die die bestimmte Business-Logik und die Use-Cases beinhaltet => Was kann die Applikation nach außen hin?
- Eine Ebene, die zwischen den Use-Cases und z.B. dem UI "vermittelt". Objekte der Domäne, die sich mitunter ändern können, sollen möglichst keine Änderungen im UI oder ähnliches nachsichziehen.
- Eine Ebene, die zur Darstellung gedacht ist. Sie zeigt prinzipiell nur die Ergebnisse an, besitzt ein eigenes Model, welches speziell für das UI vorgesehen ist, sodass die Domäne frei von diesen Details bleibt. Diese Ebene wird häufig, im Gegensatz zum "Kern" als sehr schnelllebig bezeichnet und sollte ohne Probleme austauschbar sein, ohne dass der Rest der Applikation davon beiinflusst wird.
Dieser Aufbau wird häufig mit einer Zwiebel verglichen, da sich die verschiedenen Schichten "ummanteln". Primäres Ziel ist es, den technologisch unabhängigen Kern sowie die Business-Logik von den konkreten Details der Applikation wie z.B dem UI zu trennen, damit Abhängigkeiten außen schnell ausgetauscht werden bzw. verändert werden können.
[(1 Klasse, die die Dependency Rule einhält und eine Klasse, die die Dependency Rule verletzt); jeweils UML der Klasse und Analyse der Abhängigkeiten in beide Richtungen (d.h., von wem hängt die Klasse ab und wer hängt von der Klasse ab) in Bezug auf die Dependency Rule]
In dieser Applikation halten prinzipiell alle Klassen die Dependency-Rule hinsichtlich dem "Fluss" der Abhängigkeiten ein. Klassen innerer Schichten besitzen keine Abhängigkeiten nach Außen. Dies wird u.a. durch den Aufbau des Maven Projektes selbst gewährleistet, da nur die äußeren Schichten/Module weiter innen liegende Module als Abhängigkeit definiert haben. Beispielsweise werden Repositories in der Domain-Schicht als Interface deklariert und erst außen konkret implementiert.
Wie im UML Diagramm zu sehen ist besitzt das Interface ConfigRepository selbst nur Dependencies innerhalb der eigenen
Schicht, wird aber in der Application-Schicht genutzt und von PropertiesConfigRepository in der Plugin-Schicht
implementiert. Die Klasse ConfigServiceImpl ist ebenfalls nicht abhängig von der Klasse aus der Plugin-Schicht, was
eine Verletztung der Dependency-Rule darstellen würde, sondern stattdessen abhängig vom Interface.
Über eine Dependency Injection wird schließlich in der Plugin-Schicht die konkrete Implementierung der Repository "injected".
Selbiges gilt für den AgentService. Dieser hat ausschließlich Abhängigkeiten in Richtung Domain-Layer bzw. eine
Vererbung auf derselben Ebene. Nach außen Richtung Adapter bzw. Plugin Schicht besteht keinerlei Abhängigkeit. In der
Adapter-Schicht ist einzig und allein die AgentServiceFacadeImpl vom Service abhängig.
Die Facades bieten der Plugin-Schicht ein einheitliches Interface an. Somit kann sich das Domain-Model änndern, ohne dass das
Ui davon beeinflusst wird.
[jeweils 1 Klasse zu 2 unterschiedlichen Schichten der Clean-Architecture: jeweils UML der Klasse (ggf. auch zusammenspielenden Klassen), Beschreibung der Aufgabe, Einordnung mit Begründung in die Clean-Architecture]
Die abstrakte Klasse Agent ist eines der Kernstücke der Domain. Der Agent kann Aktionen in einer Umgebung ausführen.
Die Klasse ist hier angesiedelt, da sie
- nur das "Verhalten" definiert und keine technischen Details berücksichtigt
- im Allgemeinen zur Domäne des Reinforcement Learnings gehört
- eine vorgegebene Ausführungsreihenfolge definiert, wie das Training oder eine Evaluation abläuft. Dies ist absichtlich nicht Teil der Plugin-Schicht, da hier das Domain-Model solche Invarianten sicherstellen soll
Konkrete Agenten erben von dieser Klasse und mappen die Aktionen (Integer), die sie von der Aktion Source bekommen (
siehe dazu Rückgabetyp von z.B. ActionSource#selectAction, auf konkrete Aktionen Action, die die Umgebung versteht.
Die Klasse EnvironmentServiceFacade dient als Einstiegspunkt für das UI, wenn es um das Abrufen von Environments geht.
Das UI greift dabei nicht direkt auf die Services zu und arbeit somit nicht mit Domain Objekten, sondern benutzt mehrere
Facetten. Diese sind im Adapter-Layer platziert und wandeln die Domain Objekte, die sich mitunter ändern können, in eine
speziell für UI vorgesehen Repräsentation um. Somit kann sich das Domain-Modell ändern, allerdings könnte durch das
Mapping das UI unverändert bleiben.
Innerhalb des Projektes wird die Umwandlung zwischen Domain-Objekt und der Repräsentation für das UI - den DTOs (Data Transfer Objects) -
über verschiedene Mapper wie z.B. Objekte der Klasse ActionMapper durchgeführt.
[jeweils eine Klasse als positives und negatives Beispiel für SRP; jeweils UML der Klasse und Beschreibung der Aufgabe bzw. der Aufgaben und möglicher Lösungsweg des Negativ-Beispiels (inkl. UML)]
Das SRP wird durch so gut wie jede Repository-Implementierung erfüllt. Als Beispiel wurde hier die ConfigRepository
mit der konkreten Implementierung PropertiesConfigRepository gewählt. Die Repository hat die Aufgabe, Config Einträge
aus der config.properties Datei auszulesen und in diese zu speichern. Die Repository führt dabei keine besonderen
Validierungen oder ähnliches durch, sondern ist einzig und alleine für CRUD Operationen verantwortlich und müsste auch
nur aus diesem Grund geändert werden.
Als negativ-Beispiel habe ich die Klasse SimpleEnvironmentFactory gewählt. Obwohl es für dieses kleine Projekt in
Ordnung sein mag, ist dennoch das SRP in diesem Fall verletzt. Die Klasse kümmert sich beispielsweise nicht nur um das
Erstellen einer Grid-World Umgebung, sondern auch um das Parsen der Datei, aus der eine Grid-World initialisiert werden
könnte.
Aus aktueller Sicht könnte es deswegen vorkommen, dass die Klasse aus mehr als einem Grund angepasst werden müsste:
- Zum Anpassen der Factory Methode selbst (=> Wie die Objekte erstellt werden)
- Falls sich das Format der Grid-World Datei ändert
- Falls weitere Optionen für das Erstellung von Environments unterstützt werden sollen
Zur Lösung könnte das Parsing in eine eigene Klasse ausgelagert werden. Diese Klasse würde einen bestimtes Inteface implementieren, welches die Factory für alle Aufrufe nutzen kann. Per Dependency Injection o.ä. würde die konkrete Implementierung des Parsers in die Factory gelangen.
[jeweils eine Klasse als positives und negatives Beispiel für OCP; jeweils UML der Klasse und Analyse mit Begründung, warum das OCP erfüllt/nicht erfüllt wurde – falls erfüllt: warum hier sinnvoll/welches Problem gab es? Falls nicht erfüllt: wie könnte man es lösen (inkl. UML)?]
Als klassisches Negativbeispiel für die Verletzung dieses Prinzips kann eine solche Factory genommen werden. Diese entscheidet in diesem Fall, je nach Name des Agenten, welcher Agent erzeugt werden muss. Die Fallunterscheidung, welcher konkrete Typ erstellt werden muss, geschieht mittels einer Map, die von dem Namen eines Agenten auf eine sepzielle Funktion mapped, die die Konstruktion übernimmt. Wird ein neuer Agent im Code hinzugefügt, so muss entweder
- Die Methode
createAgentselbst angepasst werden -> direkte Verletzung OCP - Eine abgeleitete Klasse erstellt werden, die für alle bestehenden Agenten
super.createAgent()aufruft. In diesem Fall muss auch die neue bzw. erweiterte Factory in die Dependency Injection oder ähnliches aufgenommen werden. Auch wenn über Polymorphie in diesem Fall das OCP erfüllt werden würde, ist dieses Konzept nicht flexibel einsetzbar, da definitiv bereits genutzte Datenstrukturen wie z.B. dieENV_CONSTRUCTORSwiederholt werden müssten, da sie in der aktuellen Version alsprivatedeklariert sind.
Abhilfe würde hier ein etwas dynamischeres Konzept schaffen. Über eine zentrale Registry könnte man für jeden
Agenten-Namen bestimmte Provider registrieren, die sich um das Erstellen eines bestimmten Agenten kümmern. Die Factory
greift auf diese Registry zu und holt sich den entsprechenden Provider aus der Map. So müsste die Factory nicht
angepasst werden.
Das Problem verlagert sich dabei allerdings auf die Registry, die nun von außen manipuliert bzw. überschrieben werden müsste.
In meinem Fall habe ich mich allerdings bewusst bei allen Factories dagegen entschieden, da mir
bei dieser Projektgröße KISS als Konzept wichtiger war.
Ein weiteres Problem könnte in der Signatur der Fabrikmethode selbst bestehen, sofern neue Agenten hinzugefügt werden, deren Konstruktur von den bisherigen abweicht. Umgangen werden könnte dies über die bereits angesprochene Subklasse. Über den Konstruktur der Factory könnten die fehlenden Parameter übergeben werden, sofern diese beim Erzeugen der Factory bekannt sind.
Obwohl die Factory streng genommen das OCP verletzt, ist der Agent selbst ein gutes Beispiel für die Nutzung dessen.
Die abstrakte Basisklasse Agent stellt die abstrakte Methode transformAction bereit und abgeleitete Klassn bzw.
konkrete Agenten implementieren diese. Die Methode wandelt den Integer der Aktion, der von der Action Source kommt in
eine für das Environment verständliche Aktion um.
Die Methode executeNextAction(), die bereits in der Basisklasse implementiert ist und die für alle Agenten
gleiche Logik zum Ausführen einer Aktion beinhaltet, ruft diese dann auf, um die konkrete Aktion zu holen.
Sämtliche Logik, die zum Trainieren des Agenten genutzt wird, bleibt unverändert, sobald ein neuer Agent hinzugefügt
wird, da diese Klassen alle entweder transformAction aufrufen oderexecuteNextAction direkt, wie im unteren Beispiel.
public void start() {
long currStep = 0;
execWhenPresent(obs -> obs.onSzenarioStart(this));
while (currStep < szenario.maxSteps()) {
final long currentStepCached = currStep;
execWhenPresent(obs -> obs.preSzenarioStep(this, currentStepCached, szenario.agent().getCurrentAverageReward()));
szenario.environment().tick();
szenario.agent().executeNextAction();
execWhenPresent(obs -> obs.postSzenarioStep(this, currentStepCached, szenario.agent().getCurrentAverageReward()));
currStep++;
}
execWhenPresent(obs -> obs.onSzenarioEnd(this, szenario.agent().getCurrentAverageReward()));
}Nützlich war dies vor allem bei den zwei unterschiedlichen Agenten MovingAgent2d und FlatMovingPullAgent, die jeweils nur
transformAction überschreiben. Sie können per Plug & Play überall eingesetzt werden.
Soll ein neuer Agent hinzugefügt werden, kann einfach eine Subclass von Agent erstellt werden, die die entsprechenden
Methoden überschreibt. SzenarioSession wird mit diesem neuen Agenten genauso problemlos verfahren wie mit allen
bereits implementieren Agenten.
Analyse Liskov-Substitution- (LSP), Interface-Segreggation- (ISP), Dependency-Inversion-Principle (DIP)
[jeweils eine Klasse als positives und negatives Beispiel für entweder LSP oder ISP oder DIP); jeweils UML der Klasse und Begründung, warum man hier das Prinzip erfüllt/nicht erfüllt wird]
[Anm.: es darf nur ein Prinzip ausgewählt werden; es darf NICHT z.B. ein positives Beispiel für LSP und ein negatives Beispiel für ISP genommen werden]
Wie im UML Diagramm zu sehen ist, ist die Klasse ConfigServiceImpl aus dem Application-Layer nicht von der konkreten
Implementierung der Repository PropertiesConfigRepository, welche in der Plugin-Schicht implementiert ist, abhängig,
sondern von dem deklarierten Interface ConfigRepository, welches eine einheitliche und technologisch unabhängige
Schnittstelle definiert. Somit kann, in diesem Fall der Service, mit beliebigen Ausprägungen der ConfigRepository
genutzt werden. Würde ConfigServiceImpl die konkrete Implementierung nutzen, wäre zusätzlich die Depdendency Rule
verletzt, da diese sich auf der Plugin-Schicht befindet.
Zusätzlich werden auf diese Weise die "technischen Details" an die äußeren Schichten verlagert.
Das Negativ-Beispiel bezieht sich hierbei auf die KlasseExecutionServiceImpl, da diese von der konkreten Implementierung der Klasse SzenarioSession abhängt.
Die Klasse SzenarioSession, die die Logik für das Ausführen des Trainings bzw. der Evaluation beinhaltet, ist eine
direkte Abhängigkeit des ExecutionServiceImpl. Sollte das Verhalten, wie das Training durchlaufen werden soll, später
angepasst werden, muss zuerst die Struktur innerhalb von ExecutionServiceImpl umgebaut werden.
In diesem einfachen Projekt ist dies nicht der Fall, weswegen es auf diese Weise gelöst wurde.
Gelöst werden könnte dies genauso wie bei den Repositories, indem ein Interface eingeführt wird und eine äußere Schicht
sich um die Details kümmert.
Zum Einsatz kommen könnte hier beispielsweise das Strategy bzw. Behaviour Pattern, welches die Logik zum Ausführen
des Trainings hinter verschiedenen Implementieren verstecken könnte.
Durch polymorphe Methodenaufrufe, die aus Sicht des Services über ein gemeinsames Interface geschehen, könnten so die
konkreten Details versteckt werden.
Sollen von Außen unterschiedliche Möglichkeiten konfigurierbar sein, wie konkret das Training ausgeführt werden soll, wäre eine weitere Factory von nöten, die die verschiedenen Sessions erstellen kann.
[jeweils eine bis jetzt noch nicht behandelte Klasse als positives und negatives Beispiel geringer Kopplung; jeweils UML Diagramm mit zusammenspielenden Klassen, Aufgabenbeschreibung und Begründung für die Umsetzung der geringen Kopplung bzw. Beschreibung, wie die Kopplung aufgelöst werden kann]
Die Klasse InMemoryAgentRepository ist ein gutes Beispiel für lose Kopplung. Um ihre Funktionalität zu
erfüllen sind, jedenfalls von außen betrachtet, ist nur ein Service und eine weitere Factory relevant. Alle Methodenaufrufe
auf die beiden Abhängigkeiten innerhalb von InMemoryAgentRepository geschehen über das jeweilige Interface (virtueller
Methodenaufruf über Interface), wie im UML Diagramm dargestellt. Die konkreten Ausprägungen der Interfaces sind sehr
leicht austauschbar und auch in den Tests dadurch leicht mockbar. Somit kann die Repository sehr isoliert getestet
werden und benötigt kein Wissen über Implementierungsdetails bzw. muss keine Annhamen über den internen Aufbau
dieser Komponenten treffen.
Ein negativ-Beispiel für geringe Kopplung zeigt sich der Beziehung zwischen den Klassen Szenario und SzenarioSession
. Die Session weist eine direkte Abhängigkeit zu Objekten der Klasse Szenario auf. Sollte sich der Aufbau eines
Szenarios ändern, z.B. das anstatt den konkreten Descriptoren nun die Namen dieser gespeichert werden (z.B. statt
AgentDescriptor nun den Namen des Agenten), könnte es zu Probleme kommen, wenn die SzenarioSession diesen benötigt. Die
Klasse müsste sich nun selbst darum kümmern, wie es an den Descriptor kommt.
Kurz: Selbst kleinere Änderungen in Szenario können ebenfalls umfangreichere Änderungen in Szenario bedeuten.
Besser wäre in diesem Fall ein Interface, welches für dieses Beispiel eine Methode getAgentDescriptor() anbieten
könnte. Konkrete Ausprägungen von Szenario müsste sich dann damit beschäftigen, wie sie an den Descriptor gelangen,
nicht die Session, die diesen eigentlich nur nutzen möchte.
[eine Klasse als positives Beispiel hoher Kohäsion; UML Diagramm und Begründung, warum die Kohäsion hoch ist]
Als Beispiel für hohe Kohäsion wurde hier die konkrete Ausprägung eines Environments ausgewählt:
Das KArmedBanditEnvironment. Das Environment besitzt prinzipiell, wie auch im UML Diagramm dargestellt, keine weiteren
Abhängigkeiten nach Außen. Dies begünstigt natürlich die Kohäsion, da alles, was die Klasse an Funktionalität ausführen möchte,
von dieser bereitgestellt werden muss.
Alle Methoden und Attribute, die die Klasse besitzt, beziehen sich einzig und alleine auf dieses konkrete Environment
und damit auf seine Hauptaufgabe.
Sie sind alle unabdingbar, damit dieses seine korrekte Funktionalität gewährleisten kann und können alle schwierig bis
gar nicht in weitere Module ausgelagert werden.
[ein Commit angeben, bei dem duplizierter Code/duplizierte Logik aufgelöst wurde; Code-Beispiele (vorher/nachher); begründen und Auswirkung beschreiben]
Commit-ID: 24c44969aa2153d42fde255d37a7f77005c2da92
Beim Überprüfen der gültigen Ranges für die Record-Werte (RLSettings.java) wurde sehr oft dasselbe If-Statement wiederholt, obwohl es jedes mal eine identische Aussage hat, nur mit einem anderen Wert. Da zu erwarten ist, dass mit Algorithmen, die noch implementiert werden, neue Werte dazukommen, könnte diese Überprüfung schnell unübersichtlich werden. Zur Behebung wurde die Logik für das Überprüfen und Werfen der Exception in eine eigene, statische Methode ausgelagert. So kann die Überprüfung der Werte sehr einfach erweitert werden. Zusätzlich lässt sich ohne großes Refactoring die Error Message für alle Werte einfach anpassen, falls z.B. ein Präfix o.ä. hinzugefügt werden soll.
Vorher:
public RLSettings {
if (learningRate < 0 || learningRate > 1)
throw new IllegalArgumentException("Die Lernrate darf nur im Interval [0, 1] liegen.");
if (discountFactor < 0 || discountFactor > 1)
throw new IllegalArgumentException("Der Discount Factor darf nur im Interval [0, 1] liegen.");
if (explorationRate < 0 || explorationRate > 1)
throw new IllegalArgumentException("Die Erkundungsrate darf nur im Interval [0, 1] liegen.");
if (agentRewardStepSize < 0 || agentRewardStepSize > 1)
throw new IllegalArgumentException("Die Agent-Reward-Schrittrate darf nur im Interval [0, 1] liegen.");
}Nachher:
public RLSettings {
checkArgumentRangeZeroToOneInclusive(learningRate, "Die Lernrate darf nur im Interval [0, 1] liegen.");
checkArgumentRangeZeroToOneInclusive(discountFactor, "Der Discount Factor darf nur im Interval [0, 1] liegen.");
checkArgumentRangeZeroToOneInclusive(explorationRate, "Die Erkundungsrate darf nur im Interval [0, 1] liegen.");
checkArgumentRangeZeroToOneInclusive(agentRewardStepSize, "Die Agent-Reward-Schrittrate darf nur im Interval [0, 1] liegen.");
}
private static void checkArgumentRangeZeroToOneInclusive(double value, String error) {
if (value < 0 || value > 1)
throw new IllegalArgumentException(error);
}[Nennung von 10 Unit-Tests und Beschreibung, was getestet wird]
In der folgenden Tabelle ist eine kleine Auswahl aus unterschiedelichen Unit-Tests zusammengefasst:
| Unit Test | Beschreibung |
|---|---|
| ExecutionServiceTest#startSzenarioShouldCallAllObserverMethods | Testet, ob die beiden Methoden der Klasse ExecutionServiceImpl alle Observer Methoden häufig gebug aufrufen bzw. ob die Anzahl der Aufrufe stimmen. |
| ExecutionServiceTest#startEvaluationShouldNotCallPersistStore | Testet, ob die Methode startEvaulation den evaulierten ActionValueStore auch tatsächlich nicht speichert. |
| ExecutionServiceTest#startSzenarioWithUnknownDescriptorsShouldThrow | Testet, ob die korrekten Fehlermeldungen als Exception geworfen werden, sofern Eingaben nicht korrekt sind. |
| EnvironmentMapperTest#dtoAttributesShouldHaveSameValue | Testet, ob das Mapping zwischen dem Domain-Objekt EnvironmentDescriptor und dem DTO EnvironmentDescriptorDto korrekt funktioniert. |
| ActionValueStoreTest#getMaxActionValueShouldReturnMaximumEntryOfState | Testet, ob die getMaxActionValue der Klasse ActionValueStore immer korrekt die aktuell Beste Aktion für den übergebenen Zustand findet. Diese Funktion bildet den Grundstein für viele Algorithmen. |
| GridWorldEnvironmentTest#environmentShouldNotBeAbleToMoveToForbiddenState | Testet, ob das Environment in einen Zustand tranferiert werden kann, in dem der Agent auf einem verbotenen Zustand steht, sofern er sich bewegt. |
| GridWorldEnvironmentTest#positionShouldResetOnTerminalOrBombState | Testet, ob die Umgebung in einen Zustand tranferiert werden kann, in dem der Agent das Grid verlässt. |
| GridWorldEnvironmentTest#actionsShouldMoveAgent | Testet, ob die Umgebung für alle unterstützten Aktionen den korrekten Zustand annimmt. |
| KArmedBanditEnvironmentTest#environmentMoveActionShouldNotLeaveBoundary | Testet, ob die Umgebung mit Bewegungsbefehlen nach rechts/links in einen Zustand überführt werden kann, der außerhalb der Anzahl an zu verfügung stehenden Bandits liegt. |
| KArmedBanditEnvironmentTest#getRewardShouldMatchPrecomputedArray | Testet, ob die getReward Methode des KArmedBanditEnvironment je nach gezogenem Hebel den korrekt Reward zurückgibt. |
[Begründung/Erläuterung, wie 'Automatic' realisiert wurde]
Automatic wurde über die Testing-Bibliothek JUnit realisiert, die automatisch alle Testklassen sucht und alle darin
befindlichen Tests ausführt. Die Tests selber können über mvn test automatisch ausgeführt werden und der Nutzer wird
entsprechend benachrichtigt, sofern Tests fehlgeschlagen sind. Über GitHub Action können zusätzlich, nach jedem Commit,
die Tests ausgeführt werden. So ist gewährleistet, dass bei Änderungen schnell erkannt werden kann, dass die Änderungen
eventuell unerwünschte Effekte hatten.
Zusätzlich zu den automatischen Unit-Test werden neue Code-Smells, Bugs oder Security Probleme vollautomatisch durch SonarCloud überwacht. Auch warnt das Tool davor, sofern neuer Code ungetestet ist oder andere Probleme aufweist.
[jeweils 1 positives und negatives Beispiel zu 'Thorough'; jeweils Code-Beispiel, Analyse und Begründung, was professionell/nicht professionell ist]
Besonders für die Tests der Environments war es wichtig sicherzustellen, dass alle möglichen Pfade abgedeckt sind und das Environment kein Fehlerverhalten aufweist, da dadurch die Trainingsergebnisse verfälscht werden könnten bzw. komplett nutzlos wären. Wie im unteren Beispiel zu erkennen ist, wurden zunächst alle validen Aktionen getestet (Bewegung in 4 Richtungen sowie nichts tun). Um sicherzugehen, dass andere Aktionen nichts verändern, werde diese separat im Test darunter überprüft.
Durch die Tests werden sowohl Fälle getestet, mit denen die Objekte normalerweise konfrontiert sind (d.h. korrekte Aktionen), als auch Fälle, die absichtlich die Environments auf Fehlverhalten prüfen sollen.
@Test
void actionsShouldTransitionEnvironmentToNewState() {
execActionAndCompareState(Action.MOVE_X_DOWN, 0);
execActionAndCompareState(Action.MOVE_Y_UP, 2);
execActionAndCompareState(Action.MOVE_Y_DOWN, 0);
execActionAndCompareState(Action.MOVE_X_UP, 1);
execActionAndCompareState(Action.DO_NOTHING, 1);
}
@Test
void unsupportedActionsShouldReturnFalseAndNotChangeState() {
execInvalidActionAndCompareState(Action.PULL);
execInvalidActionAndCompareState(Action.MOVE_Z_UP);
execInvalidActionAndCompareState(Action.MOVE_Z_UP);
}
private void execActionAndCompareState(Action action, int expectedState) {
assertTrue(environment.executeAction(action, 1));
assertEquals(expectedState, environment.getCurrentState());
}
private void execInvalidActionAndCompareState(Action action) {
int preState = environment.getCurrentState();
environment.executeAction(action, 1);
assertEquals(preState, environment.getCurrentState());
}Ein negativ-Beispiel ist im unteren Code-Beispiel abgebildet.
Hier wird der Update-Schritt des Algorithmus' QLearning anhand von wenigen Beispielwerten getestet und mit einer fixen Konfiguration. Die Learning-Rate wurde in allen
QLearning-Tests auf 1 (neutrales Element der Multiplikation) gesetzt, was den absolut einfachsten Fall darstellt. Obwohl
der Algorithmus hier korrektes Verhalten aufweist und die Code Coverage 100% erreicht, könnte es eventuell mit sehr kleinen oder großen Werten für die
Learning-Rate zu Problemen kommen, bzw. sich Fehler in der Formel offenbaren (ob die Learning Rate z.B. überhaupt
korrekt berücksichtigt wird).
Behoben werden kann dies über zusätzliche Tests mit unterschiedlichen Konfigurationen, um solche Fehler zu offenbaren.
Auch Tests mit möglichen Edge-Cases wären denkbar z.B. mit Werten, die nicht auftreten dürfen, wie z.B. negative Zahlenwerte
oder NULL Parameter.
@Test
void learningShouldAdjustOldStateActionPairCorrectly() {
// !IMPORTANT! Learning Rate is 1 and Discount Factor is 1, so it should reach target instantly
learning.criticiseAction(0, 0, 1, 3.141);
assertEquals(3.341, store.getActionValue(0, 0));
learning.criticiseAction(1, 2, 2, 0);
assertEquals(0.2, store.getActionValue(1, 2));
}[jeweils 1 positives und negatives Beispiel zu 'Professional'; jeweils Code-Beispiel, Analyse und Begründung, was professionell/nicht professionell ist]
@BeforeEach
void prepare() {
grid = new int[2][3];
grid[0][0] = GridWorldEnvironment.STATE_TERMINAL;
grid[1][0] = GridWorldEnvironment.STATE_SPAWN;
grid[0][1] = GridWorldEnvironment.STATE_NORMAL;
grid[1][1] = GridWorldEnvironment.STATE_BOMB;
grid[0][2] = GridWorldEnvironment.STATE_FORBIDDEN;
grid[1][2] = GridWorldEnvironment.STATE_FORBIDDEN;
environment = Mockito.spy(new GridWorldEnvironment(grid));
}
@Test
void actionsShouldTransitionEnvironmentToNewState() {
execActionAndCompareState(Action.MOVE_X_DOWN, 0);
execActionAndCompareState(Action.MOVE_Y_UP, 2);
execActionAndCompareState(Action.MOVE_Y_DOWN, 0);
execActionAndCompareState(Action.MOVE_X_UP, 1);
execActionAndCompareState(Action.DO_NOTHING, 1);
}
private void execActionAndCompareState(Action action, int expectedState) {
assertTrue(environment.executeAction(action, 1));
assertEquals(expectedState, environment.getCurrentState());
}Positiv an diesem Beispiel ist der klare Name des Tests actionsShouldTransitionEnvironmentToNewState. Sobald man den
Namen liest und die Zusammenhänge in der Domäne verstanden hat, sollte klar sein, dass hier die verschiedenen Aktionen
getestet werden, die das Environment unterstützt. Als Konsequenz auf jede Aktion geht die Umgebung in einen neuen
Zustand über, den es zu prüfen gilt. Genutzt werden wohlbekannte Assertions von JUnit wie z.B. assertEquals, in dem
der erwartete Zustand mit dem aktuellen Zustand der Umgang nach der Aktion verglichen wird. Des Weiteren wurde versucht
die Code-Duplikation durch das Einführen von einer neuen Methode zu reduzieren.
Um die Tests möglich frei von Initialisierungscode zu halten, wird vor jedem Test die Methode prepare() ausgeführt, die
das Environment und alle zum Testen relevante Attribute zurücksetzt und in diesem Fall ein Beispielgrid initialisiert.
Somit kann ein Test genau eine bestimmte Gruppe an zusammenhöngenden Pfaden testen, ohne auf das Wie komme ich an die Variablen? rücksicht nehmen zu müssen.
Ein unter Umständen wenig problematisches, allerdings dennoch vorhandenes Negativbeispiel ist ein klassischer Fall der Code-Duplication. Im Folgenden ist dies anhand von zwei einfachen Fällen in den Tests dieses Projektes dargestellt:
GreedyPolicy.java
@BeforeEach
void prepare() {
ActionValueStore store = new ActionValueStore(
new double[][]{
{ 0.0, 1.0, 2.0 },
{ 0.0, 3.0, 1.0 },
{ -1.0, -2.0, -4.0 }
}
);
policy = new GreedyPolicy(store, new RLSettings(
0.0, 0.0, 1000, 0.0
));
}PolicyTest.java
@BeforeEach
void prepare() {
store = new ActionValueStore(new double[][]{
{ 0.0, 1.0, 2.0 },
{ 0.0, 3.0, 1.0 },
{ -1.0, -2.0, -4.0 }
});
settings = new RLSettings(
0.0, 0.0, 0.0, 0.0
);
policy = new FakePolicy(store, settings);
}In beiden Beispielen werden sehr ähnliche Code-Abschnitte genutzt, vor allem wenn es um das Initialisieren
des RLSettings Objektes geht. Auch wird zwei bzw. mehrmals derselbe oder ein ähnlicher ActionValueStore genutzt, was
zu unnötiger Code Duplikation führt und damit zu einem erhöhten Wartungsaufwand, falls sich etwas an den Konstruktoren o.ä.
ändern sollte.
Gelöst werden könnte dies über eine separate Klasse mit statischen Methoden, die solche "Default" Objekte bereitstellt (
z.B. eine leeres RLSettings Objekt). Auch könnten unter Umständen das Builder-Pattern genutzt werden, um die
Erstellung von solchen Objekten abzukürzen, damit diese nicht mehr Platz einnehmen als nötig.
[Code Coverage im Projekt analysieren und begründen]
In der folgenden Analyse der Code-Coverage sind nur die Module des tatsächlichen Reinforcement Learning Projektes
beinhaltet. Das Utils Modul, welches den CLI-Parser und die Dependency Injection zur Verfügung stellt wurde bewusst
davon ausgenommen, da dieses nicht wirklich Logik für das Reinforcement Learning an sich bereitstellt und "nur" als
Exkurs zum Lernen programmiert wurde.
Dennoch sind selbstverständlich einige Aspekte dieses Moduls getestet, allem voran die zahlreichen Funktionen,
die die Reflection und damit das Kernstück der Dependency Injection durchführen. Auch ist der InjectionContext selbst mit Tests versehen,
um das Mapping der Interfaces auf konkrete Klassen zu testen.
Triviale Pfade wie z.B. einzelne Get Methoden oder Value-Objekte, die ausschließlich Daten beinhalten wurden nicht getestet, da hier das Aufwand/Nutzen Verhältnis nicht wirklich gegeben ist.
| Modul/Layer | Coverage | Begründung |
|---|---|---|
| Domain | ca. 55% | Die Tests decken alle wichtigen Kernfunktionalitäten ab, wie z.B alles was Logik beinhaltet und grundlegende Funktionalität nach außen bereitstellt (Agent Klasse z.B.). Teilweise nicht durch Tests abgedeckt sind Exceptions oder die Value-Objects, da diese teilweise nur triviale Get-Methode beinhalten. |
| Applikation | ca. 77% | Die einzigen Services im Applikations-Layer, die tatsächlich wichtige Logik beinhalten, sind der ExecutionService und der ConfigService bzw. deren Implementierung. Beide Services werden entsprechend soweit wie möglich mit gemockten Dependencies isoliert getestet. Die übrigen Services wie z.B. AgentService oder EnvironmentService reichen alle Calls momentan 1 zu 1 an die Repository weiter. Sie existieren aus dem Grund, dass wenn die Services später erweitert werden sollen, nicht erst in anderen Klassen auf einen Service gewechselt werden muss. Beide Services sind nahezu 100% getestet. Des Weiteren werden wichtige Kernfunktionalitäten wie die Implementierten Environments, Algorithmen sowie verschiedenen Policy-Varianten zu fast 100% abgedeckt. |
| Adapters | ca. 60% | In der Adapter-Schicht werden momentan nur die wichtigsten Klassen getestet, welche im Moment die Mapper sind. Diese mappen ein bestimmtes Domain-Objekt auf den entsprechenden DTO. Zusätzlich wird für die ExecutionServiceFacade getestet, ob die startTraining bzw. startEvaluation Methoden die richtige Methode im gemockten Service aufrufen. Die übrigen Fassaden sind momentan ungetestet, da diese ausschließlich den entsprechenden Mapper aufrufen und keine testenswerte Logik beinhalten. |
| Plugin | ca. 15% | Das aktuell am wenigsten getestete Modul ist das Plugin-Modul, welches das CLI beinhaltet. Auch hier wird im Moment nur für den RunCommand getestet, ob je nach Parameter die richtige Methode in der ExecutionServiceFacade aufgerufen wird. Dies ist sehr wichtig, da diese beiden Methode den Eintrittspunkt für die gesamte Funktionalität darstellen. Alle übrigen Commands printen die DTOs eins zu eins in die Konsole. Die genaue Ausgabe in der Konsole zu testen erschien nicht sinnvoll bzw. das Aufwand-Nutzen Verhätnis ist hier nicht wirklich gegeben. |
[Analyse und Begründung des Einsatzes von 2 Fake/Mock-Objekten; zusätzlich jeweils UML Diagramm der Klasse]
Ein Interface, welches häufig gemockt wird, damit keine konkrete Implementierung erforderlich ist, ist das
Interface Environment. Den Gettern werden dabei spezifische Rückgabewerte zugewiesen, die teilweise von den
übergebenen Parametern an die Methoden abhängig sind. Zusätzlich dazu ist das Mocken dieses Interfaces recht einfach, da
es sehr simpel aufgebaut ist und keine komplizierten Eingaben bzw. Ausgaben sowie wenige Methoden besitzt.
Beispielsweise wird dieser Mock in der Klasse SimpleAgentFactoryTest genutzt, um die SimpleAgentFactory zu testen.
Für die Funktionalität ist zunächst kein konkretes Environment erforderlich, allerdings sollte es, auch im Zuge späterer
Erweiterungen auch nicht NULL sein.
In den Tests für die Factory ist zusätzlich kein State relevant, sondern es soll nur das Verhalten der Methoden getestet werden, was den perfekten Anwendungsfall für solche Mocks bietet.
Ein weiteres gemocktes Interface ist SzenarioExecutionObserver welches in der Klasse ExecutionServiceTest dazu
genutzt wird genau zu überprüfen, wie oft die verschiedenen Methoden aufgerufen werden. Beispielsweise sollte die
Methoden onSzenarioStart und onSzenarioEnd, per Definition, nur einmal aufgerufen werden. Genauso verhält es sich
mit den Methoden preSzenarioStep und postSzenarioStep, die so oft wie die Anzahl der Szenarioschritte aufgerufen
werden sollten. Mockito bietet dafür die Methoden verify() und times() an, mit denen sich die genaue Anzahl der
Aufrufe ermitteln lässt, wie unten am Codebeispiel zu erkennen ist.
@Test
void startSzenarioShouldCallAllObserverMethods() throws StartSzenarioException {
executionService.startTraining(
"best-agent",
"best-environment",
"",
10,
0,
Optional.of(observer));
verify(observer, times(1)).onSzenarioStart(any());
verify(observer, times(1)).onSzenarioEnd(any(), anyDouble());
verify(observer, times(10)).preSzenarioStep(any(), anyLong(), anyDouble());
verify(observer, times(10)).postSzenarioStep(any(), anyLong(), anyDouble());
verify(observer, times(1)).onActionStorePersisted(any());
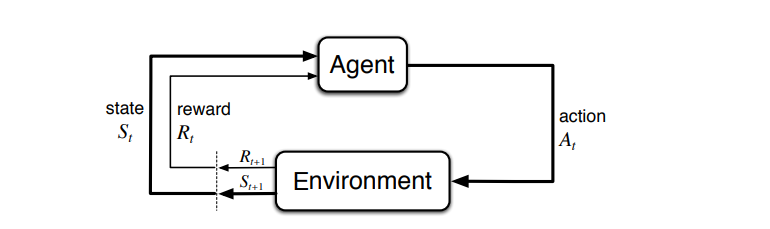
}
[4 Beispiele für die Ubiquitous Language; jeweils Bezeichung, Bedeutung und kurze Begründung, warum es zur Ubiquitous Language gehört]
Sämtliche Begriffe gehören der Domäne des Reinforcement Learnings an. Die grobe Struktur eines einfachen Systems, welches aus den Komponenten Agent und Environment besteht. Ein Agent kann dabei die Umgebung für Aktionen beeinflussen, die daraufhin in einen neuen Zustand übergeht und dem Agenten eine Belohnung bzw. Bestrafung zuweist. Die Bedeutung dieser und weiterer Begriffe ist in der folgenden Tabelle zusammengefasst:
| Bezeichung | Bedeutung | Begründung |
|---|---|---|
| Umgebung/Environment | Eine Umgebung bzw. Environment stellt ein Umfeld für Agenten zur Verfügung. Jede Umgebung erlaubt dabei ein bestimmtes Subset an Aktionen. Zur Vereinfachung sind die Environments in diesem Projekt eine Art Controller, der zugleich den Zustand über z.B. die aktuelle Position des Agenten beinhaltet. In klassischen Implementierung würde dies eine separate Engine tun, was allerdings das Projekt nur verkomplizieren würde. | Die Umgebung ist neben dem Agenten ein zentraler Bestandteil der Domäne. Ohne eine Umgebung kann ein Reinforcement Learning System, wie oben abgebildet, nicht funktionieren. Es ist deshalb wichtig, dass die klare Bedeutung festgestellt wird. Mit einer Umgebung ist deswegen nicht die Entwicklungsumgebung o.ä. gemeint, sondern die Stellung dieser Komponente im Reinforcement Learning. |
| Agent | Ein Agent ist ein Akteur innerhalb einer Umgebung. Der Agent kann verschiedene Aktionen ausführem. die die Umgebung auf eine bestimmte Beweise beinflussen und ihren Zustand ändern. | Für den Agenten gilt dasselbe wie für die Umgebung. Der Agent ist der zentrale Akteur und besitzt ebenfalls eine zentrale Bedeutung. Der Agent ist zudem ein sehr wichtiger Grundbegriff des Reinforcement Learnings. |
| Policy | Eine Policy ist prinzipiell nur ein Hinweisgeber, der einem Agenten sagt, welche Aktion in welchem Zustand wie sinnvoll ist. Anschaulich bestimmt die Policy die Aktion A, wie oben im Bild dargestellt. | Mit einer Policy wird häufig ein Regelwerk oder ähnliches gemeint, was nicht der Bedeutung eines Hinweisgebers bzw. Kommandeurs entspricht, wie in diesem Fall. |
| Algorithmus | Ein Algorithmus modifiziert eine Policy, damit diese bessere Ergebnisse erzielt. Der Algorithmus macht einen Agenten somit lernfähig. | Der Begriff Algorithmus ist sehr vielseitig besetzt. In diesem konkreten Fall geht es ausschließlich um den Fakt, dass ein Algorithmus einen Handlungsvorschrift darstellt, die den Agenten mit voranschreitender Zeit besser macht, in dem was er tut. |
[UML, Beschreibung und Begründung des Einsatzes einer Entity; falls keine Entity vorhanden: ausführliche Begründung, warum es keines geben kann/hier nicht sinnvoll ist]
Innerhalb dieses Projektes gibt es leider keine Entities im klassischen Sinne, die einen typischen Lifecycle aufweisen.
Die einzigen Objekte, die eine wirkliche "Identität" besitzen und auch über diese Abgerufen bzw. abgespeichert werden
können, sind die Descriptoren, wie am Beispiel der Klasse AgentDescriptor dargestellt. Alle Descriptoren beinhalten
Metadaten über einen anderen Typ. In diesem Fall beschreibt ein AgentDescriptor, dass ein bestimmter Agent mit dem
Namen name existiert und dieser z.B. actionSpace Aktionen zur Verfügung hat. Dadurch muss keine konreket Instanz
eines Agenten vorliegen, um seine Eigenschaften zu beschreiben. Alle Descriptoren sind über einen Namen eindeutig
identifizierbar und können über diesen durch die entsprechende Repository abgerufen werden. Da die Descriptoren über die
Laufzeit des Programms nicht gelöscht werden können, existieren diese quasi "ewig".
Wichtig, besonders bei den Descriptoren, ist, dass diese eindeutig einem Agenten zugeordnet werden können,
da sie als Grundlagen zur Erstellung des konkreten Typs benutzt werden, den sie beschreiben.
[UML, Beschreibung und Begründung des Einsatzes eines Value Objects; falls kein Value Object vorhanden: ausführliche Begründung, warum es keines geben kann/hier nicht sinnvoll ist]
Ein häufig eingesetztes Value Object sind Objekte der Klasse RLSettings. Objekte der Klassen repräsentieren eine
einfache, identitätslose Instanz, welche globale Einstellungen zum Reinforcement Learning beinhaltet. Jedes Objekt ist
Read-Only. Sollte eine Änderung nötig sein, so wird ein neues erstellt.
Das Value Object ist in diesem Fall ideal, da eine Komponente, die die Settings verwendet, diese nicht verändern darf.
Des Weiteren sollen bestehende Trainings o.ä. nicht durch eine Änderung der Einstellung beeinflusst werden.
Beispiel, in dem ein neues Objekt erstellt wird, um einen bestimmten Wert zu überschreiben:
public GreedyPolicy(ActionValueStore actionValueStore, RLSettings settings){
super(actionValueStore, new RLSettings(
settings.learningRate(),
settings.discountFactor(),
0, // Setze Explorations-Rate auf 0, sodass EpsilonGreedyPolicy nicht mehr erkundet.
settings.agentRewardStepSize()
));
} [UML, Beschreibung und Begründung des Einsatzes eines Repositories; falls kein Repository vorhanden: ausführliche Begründung, warum es keines geben kann/hier nicht sinnvoll ist]
Abgeleitete Klasse des Interfaces ConfigRepository sind dafür zuständig, die gespeicherten Einträge der Config zu
verwalten. Die Aufgaben sind sowohl das Einlesen als auch das Modifizieren (Hinzufügen). Da für alle Schichten die
konkrete Herkunft der Config-Items egal ist, wird dieses unwichtige Detail über das Interface abstrahiert.
Des Weiteren wird durch diese Repository und die damit verbundene Datei auf dem Dateisystem für alle anderen Komponenten eine Single Source of Truth geschaffen. Alle Abfragen gehen über die Repository und es gibt keine zweite Datenstruktur, die eventuell mit der Repository in Konflikt stehende Daten hält.
[UML, Beschreibung und Begründung des Einsatzes eines Aggregates; falls kein Aggregate vorhanden: ausführliche Begründung, warum es keines geben kann/hier nicht sinnvoll ist]
Innerhalb dieses Projektes existieren viele Klassen, die aus mehreren anderen Domain-Objekten bestehen, diese speichern oder benötigen, um ihre Funktion zu erfüllen.
Dazu gehören u.a. SzenarioSession mit DescriptorBundle, Agent sowie die Lernalgorithmen.
Keine dieser Klassen ist allerdings, mit Ausnahme von DescriptorBundle, zum Datenaustausch gedacht, sondern erfüllt eine
spezielle, ihr zugewiesene Funktion.
Auch wird keine der Klasse in Repositories oder ähnliches genutzt, um z.B. sicherzustellen, dass stets das gesamte Objekt
gespeichert und somit für alle Teile des Aggregates ein konsistenter Zustand gewährleistet wird.
Alle Objekte, die eine Identität besitzen wie z.B. AgentDescriptor oder andere Descriptoren, sind völlig unabhängig voneinander abrufbar
und so ist es auch gedacht.
Die Entities besitzen in diesem Fall keine wirkliche Beziehung zueinander, da sie nur einen anderen Typ "beschreiben".
Ein AgentDescriptor trifft z.B. Aussagen über die Struktur eines konkreten Agenten, steht allerdings in keinster Weise in einer direkten Beziehung zu diesem.
Anders sieht es bei den konkreten Typen aus, die sie beschreiben, denn ein Agent benötigt zwingend ein Environment, um zu funktionieren.
Es ist somit nicht sinnvoll, in z.B. Repositores ein Aggregate zu verwenden bzw. ein Aggregate-Root festzulegen, über den
einheitlich der Zugriff auf mehrere Entities geschieht, da alle Entities im Projekt völlig unabhöngig voneinander existieren und
verwendet werden können.
Commit-ID: 28d6e5b4b81c28e6eb989d5d95b44936ac9e6813
Dieser Code Smell ist während der Einführung der Klasse ActionValueStore aufgefallen. An zwei Stellen im Code wurde
für einen gegebenen Zustand die Aktion mit dem maximalen Value benötigt. Diese Funktionalität war davor separat an zwei
Stellen zu finden (Klasse QLearning + EpislonGreedyPolicy). Behoben wurde der Code-Smell durch das Verschieben des Codes in eine
gemeinsame Methode in der Klasse ActionValueStore.
Vorher, an beiden Stellen:
double highestValue = Double.MIN_VALUE;
int bestAction = 0;
double[] values = store.getActionValues(newState);
// Suche höchsten Wert
for (int i = 0; i < values.length; ++i) {
// Wert größer als vorher?
if (values[i] > highestValue) {
highestValue = values[i];
bestAction = i;
}
}Nachher, ausgelagert in externe Methode:
ActionValueStore.ActionValueEntry maxEntry = store.getMaxActionValue(newState);
int bestAction = maxEntry.action();
int bestValue = maxEntry.value();[jeweils 1 Code-Beispiel zu 2 Code Smells aus der Vorlesung; jeweils Code-Beispiel und einen möglichen Lösungsweg bzw. den genommen Lösungsweg beschreiben (inkl.__(Pseudo-)Code)]
Die createGridWorldEnvironment() Methode der Klasse SimpleEnvironmentFactory hatte sich anfangs nur mit dem
Erstellen einer Grid-World beschäftigt, die eine konfigurierbare Höhe bzw. Breite besaß. Später wurde die Möglichkeit
hinzugefügt, die Grid-World über eine Datei zu initialisieren. Das Parsen bzw. Auslesen der Datei wurde in dieselbe
Methode eingebaut (siehe Vorher), weswegen diese, jedenfalls aus meiner Wahrnehmung heraus, recht unübersichtlich wurde.
Es war ohne Kontext nicht mehr wirklich verständlich, welchen konkreten Zweck die Methode besaß. (Soll sie Parsen? Wenn
ja, was genau? ...)
Um dies zu beheben wurde der Parsing Teil in eine eigene Methode ausgelagert, die mit dem Namen parseGridWorldFile()
versehen wurde, der eindeutig beschreibt, welche Aufgabe der Code besitzt (Siehe Nachher).
Vorher:
private GridWorldEnvironment createGridWorldEnvironment(Map<String, String> parameters) throws EnvironmentCreationException {
if (!parameters.containsKey("from")) {
if (!parameters.containsKey("height") || !parameters.containsKey("width"))
throw new RuntimeException("");
try {
Integer height = Integer.parseInt(parameters.get("height"));
Integer width = Integer.parseInt(parameters.get("width"));
return new GridWorldEnvironment(height, width);
} catch (NumberFormatException e) {
throw new EnvironmentCreationException("Höhe oder Breite konnten nicht gelesen werden!", "grid-world");
}
}
// Das Parsen könnte man noch in eine eigene Klasse auslagern und über Interface in dieses Objekt injecten,
// aber für dieses einfache Beispiel ist es denke ich so O.K.
String from = parameters.get("from");
Path fromPath = Paths.get(from);
try {
List<String> lines = Files.readAllLines(fromPath);
int[][] grid = new int[lines.get(0).length()][lines.size()];
for (int i = 0; i < lines.size(); i++) {
char[] chars = lines.get(i).toCharArray();
for (int j = 0; j < chars.length; j++) {
int num = chars[j] - '0';
grid[j][i] = num;
}
}
return new GridWorldEnvironment(grid);
} catch (IOException e) {
throw new EnvironmentCreationException(
String.format("Die Datei '%s' konnte nicht korrekt gelesen werden!", from), "grid-world");
}
}Nachher:
private GridWorldEnvironment createGridWorldEnvironment(Map<String, String> parameters) throws EnvironmentCreationException {
if (!parameters.containsKey("from")) {
if (!parameters.containsKey("height") || !parameters.containsKey("width"))
throw new RuntimeException("");
try {
Integer height = Integer.parseInt(parameters.get("height"));
Integer width = Integer.parseInt(parameters.get("width"));
return new GridWorldEnvironment(height, width);
} catch (NumberFormatException e) {
throw new EnvironmentCreationException("Höhe oder Breite konnten nicht gelesen werden!", "grid-world");
}
}
String from = parameters.get("from");
Path fromPath = Paths.get(from);
try {
return new GridWorldEnvironment(parseGridWorldFile(fromPath));
} catch (IOException e) {
throw new EnvironmentCreationException(
String.format("Die Datei '%s' konnte nicht korrekt gelesen werden!", from), "grid-world");
}
}
private int[][] parseGridWorldFile(Path fromPath) throws IOException {
List<String> lines = Files.readAllLines(fromPath);
int[][] grid = new int[lines.get(0).length()][lines.size()];
for (int i = 0; i < lines.size(); i++) {
char[] chars = lines.get(i).toCharArray();
for (int j = 0; j < chars.length; j++) {
int num = chars[j] - '0';
grid[j][i] = num;
}
}
return grid;
}[2 unterschiedliche Refactorings aus der Vorlesung anwenden, begründen, sowie UML vorher/nachher liefern; jeweils auf die Commits verweisen]
| Refactoring | Begründung | Commit |
|---|---|---|
| Rename Method | Methodename deutete darauf hin, dass ausschließlich das Training mit diesem Observer beobachtet werden kann. Allerdings war dieser für alle Szenarien gedacht. | 499c5493af7518e04cb6c1e5c19ab92a38edae4f |
| Extract Method | In der Klasse RunCommand wurde, neben einigen weiteren Änderungen, die Erstellung des Observers in eine eigene Methode ausgelagert, damit die run() Methode übersichtlich bleibt. |
dbabe3845931cad4d9708778fd0c784a7cbe1ee8 |
[2 unterschiedliche Entwurfsmuster aus der Vorlesung (oder nach Absprache auch andere) jeweils sinnvoll einsetzen, begründen und UML-Diagramm]
Das Factory Pattern wird genutzt, um z.B. konkrete Visualizer zu erstellen, die eine Policy, abhängig vom Environment und Agenten, visualisieren. Da die Logik zum Erzeugen in diesem Fall recht umfangreich ist, wird diese Logik in einer eigenen Klasse gekapselt. Somit ruft beispielsweise eine Repository nur noch die Factory über das Interface auf und die konkrete Implementierung kümmert sich um das Erzeugen.
Sollten neue Typen hinzugefügt werden, kann einfach eine Subklasse einer bestehenden Factory bzw. des Interfaces erstellt werden, die diesen neuen Typen baut. Über die Dependency Injection kann diese Factory dann in sämtliche Repositories eingefügt werden, somit muss kein bestehender Code angepasst werden und sämtliche Erzeugungslogik bleibt gekapselt.
Da das Training bzw. die Evaluation eines Agenten mitunter länger dauern kann und der Nutzer über den Fortschritt
informiert werden soll, wird in diesem Projekt ein Observer eingesetzt. Der Nutzer startet ein Szenario über den Service
und spezifiziert einen Observer vom Typ SzenarioExecutionObserver.
Ohne zutun des Benutzers wird dieser Observer in einen weitere gewrapped, damit der Service selbst das Ende des Trainings
abfangen und eigene Aktionen durchführen kann.
public void startTraining(...) {
...
session.addObserver(createWrappedTrainingObserver(observer));
session.start();
}
private SzenarioExecutionObserver createWrappedTrainingObserver(Optional<SzenarioExecutionObserver> progressObserver) {
return new SzenarioExecutionObserver(){
@Override
public void onSzenarioEnd(SzenarioSession session,double averageReward){
progressObserver.ifPresent(szenarioExecutionObserver->szenarioExecutionObserver.onSzenarioEnd(session,averageReward));
DescriptorBundle bundle = session.getSzenario().metadata();
PersistedStoreInfo info = null;
try {
info = storeTrainedPolicy(
bundle.agentDescriptor().name(),
bundle.environmentDescriptor().name(),
session.getSzenario().policy());
} catch (PersistStoreException e) {
throw new RuntimeException("Es ist ein kritischer Fehler beim Speichern der Trainieren Policy auftreten!");
}
onActionStorePersisted(info);
}
// die anderen Methoden...
}
}In diesem konkreten Fall wird der Wrapper genutzt, um die nach dem Trainingsende vorhandene Policy abzuspeichern, wie im
Code Beispiel zu sehen ist.
Nachdem die Policy abgespeichert wurde, ruft der Wrapper seine eigene onActionStorePersisted(info) Methode auf,
die schließlich den Aufruf den gewrappten Observer weiterleitet (delegiert).
Streng genommen wäre dieser Wrapper nicht erforderlich, da session.start() aktuell ein blockierender Aufruf ist.
In der näheren Zukunft soll dies allerdings asynchron ausgeführt werden, womit ein Observer wie dieser zwingend erforderlich wird.
Damit sich die SzenarioSession selbst nicht um das Speichern kümmern muss bzw. überhaupt keine Kenntnis von der Existenz
eines solchen Vorganges haben muss, werden zwei getrennte Observer genutzt, wie im UML zu erkennen ist.
SzenarioProgressObserver wird dabei von der Session selbst genutzt, während der Nutzer des Services einen
SzenarioExecutionObserver spezifizieren muss. Da die Interfaces voneinander erben, kann der Observer des Services
für den im Szenario eingesetzt werden.
Das Basis-Interface SzenarioProgressObserver wird dabei an das Szenario übergeben, welche bei folgenden Ereignisse benachrichtigt:
- Vor dem Beginn des Szenarios.
- Vor jedem Schritt, der innerhalb des Szenarios ausgeführt wird.
- Nach jedem Schritt, der innerhalb des Szenarios ausgeführt wird.
- Nach dem Ende des Szenarios.